


Summary
Neuromorphic computing systems are desirable for several applications because they achieve similar accuracy to graphic processing unit (GPU)-based systems while consuming a fraction of the size, weight, power, and cost (SWaP-C). Because of this, the feasibility of developing a real-time cybersecurity system for high-performance computing (HPC) environments using full precision/GPU and reduced precision/neuromorphic technologies was previously investigated [1]. This work was the first to compare the performance of full precision and neuromorphic computing on the same data and neural network and Intel and BrainChip neuromorphic offerings. Results were promising, with up to 93.7% accuracy in multiclass classification—eight attack types and one benign class.
Since then, a BrainChip Akida 1000 chip was acquired, and Intel released the Loihi 2 chip and developed the Lava framework for establishing neuromorphic deep-learning applications. These developments and more detailed analyses are reflected in this article, with up to 98.4% accuracy achieved in classifying nine classes. Compared to the state of the art, neuromorphic technologies have much smaller SWaP-C profiles. In addition, how these systems can be applied to deployable platforms like manned aircraft or unmanned aerial vehicles (UAVs) is discussed, and additional use cases of neuromorphic computing in computer vision are reviewed.
Introduction
In the work of Zahm et al. [1], the viability of a real-time high-performance computing (HPC)-scale cybersecurity system was evaluated using full precision/GPUs and reduced precision/neuromorphic technologies in a proof of concept called Cyber-Neuro RT (e.g., Figure 1). The government operates several HPC systems for the Defense Advanced Research Projects Agency (DARPA), Oak Ridge National Laboratory (ORNL), and National Aeronautics and Space Administration’s (NASA’s) Advanced Supercomputing Division. These systems operate at much larger scales than traditional information technology (IT) domains and thus require novel tools to address their unique requirements. Neuromorphic systems were investigated because they can achieve similar accuracy as GPU systems, with a fraction of the SWaP-C budgets.

Figure 1. Nanoscience High-Performance Computing System (Source: Photo Courtesy of Argonne National Laboratory).
Zahm et al. [1] were one of the first to run the same data and neural network through full precision and Intel and BrainChip neuromorphic offerings. Intel results were generated with the Loihi 1 chip and the SNN-TB Toolbox. BrainChip results were generated via software simulation and the CNN2SNN Toolbox. Results were promising—up to 93.7% correct on a dataset with 450,000 entries and nine classes, including eight attack types; however, further research was necessary. Since then, a BrainChip Akida 1000 chip was received, and Intel released the Loihi 2 chip and developed the Lava framework for programming it. These developments and more detailed analyses were reviewed, and improved accuracy was achieved on full precision/GPU and reduced precision/neuromorphic technologies, with up to 98.4% correct. This is comparable to the state of the art presented in Gad et al. [2] and Sarhan et al. [3]. However, neuromorphic technologies have the advantage of a much smaller SWaP-C envelope, as detailed in Table 1. Because neuromorphic processors achieve similar results to GPUs and with dramatic SWaP-C savings, they are well suited for embedded or edge devices. SWaP-C savings for neuromorphic computing could be even better when using field-programmable gate arrays (FPGAs) or a licensable Intellectual Property in Register-Transfer Level (IP cores in RTL) format.
Table 1. Comparison of GPU and Neuromorphic Compute Platforms (Source for Left Image, Wikimedia [https://commons.wikimedia.org/wiki/File:Nvidia_Tesla_A100.png]; Right, Intel)

Methods
Datasets
A subset of the University of New South Wales (UNSW) TON-Internet of Things (TON-IoT) dataset was used [4]. Commonly used by cybersecurity researchers, this dataset has nine attack classes listed in Table 2 but excluding the man-in-the-middle (MITM) class due to the small sample count. Several other datasets were investigated, but only the TON-IoT was included in this work. The data-cleaning and feature-encoding process was an extension of Zahm et al. [1]. This process now infers data types more reliably, including supporting list type features such as the “all_headers” field, which contains a list of all headers of an HTTP communication using Zeek’s http.log. After examining the data by packet structure and excluding timestamp and unique identifier, deduplication and deconfliction were found to be useful. In deduplication, identical data samples were removed. In deconfliction, identical data samples with different labels were removed. This process mitigates model overfitting. After deduplication and deconfliction, ~300,000 samples remained.
Table 2. TON-IoT Dataset Summary
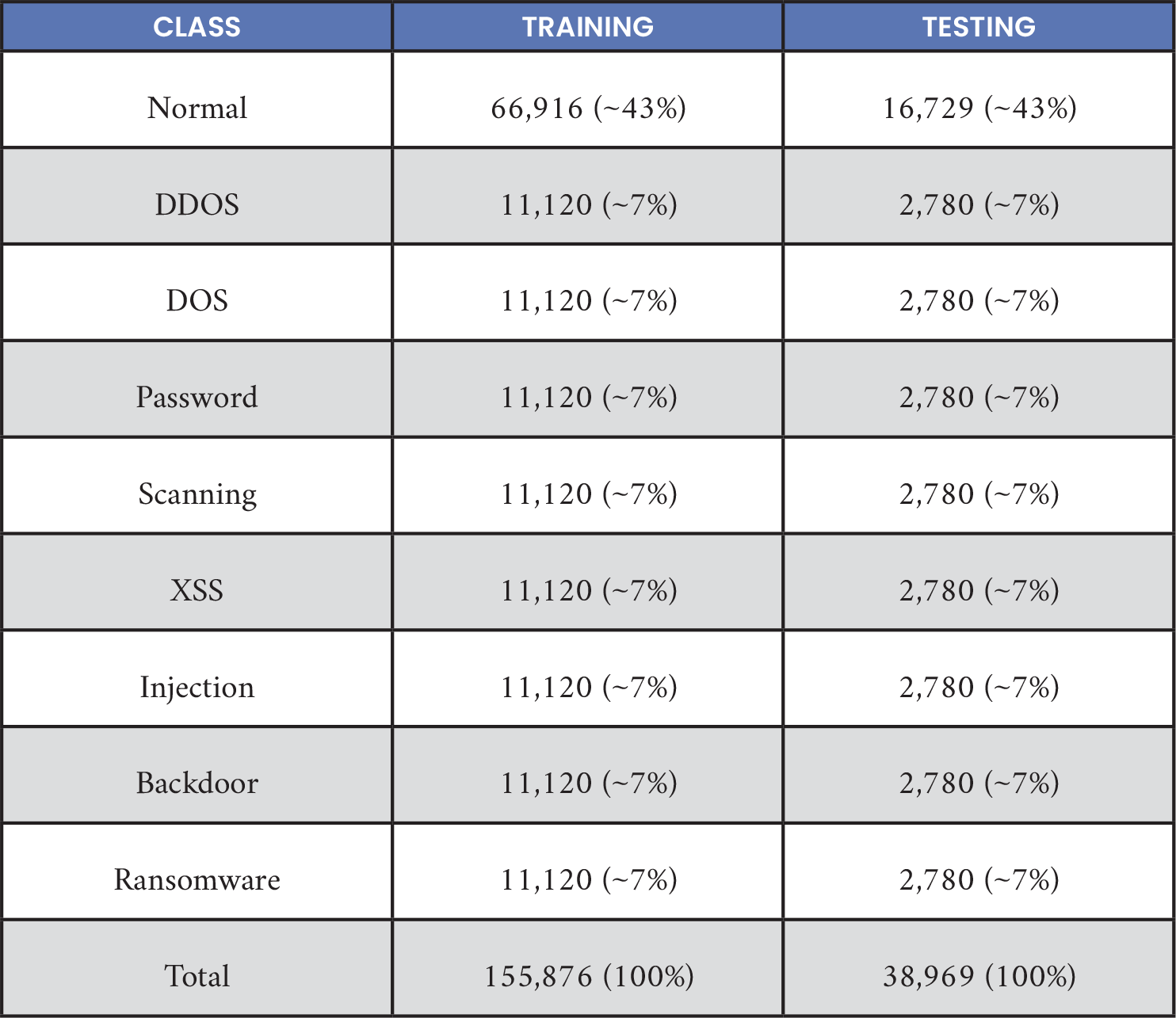
The MITM class was merged into injection attacks data due to the similarity of the two attacks and low MITM data count (0.03% of the original data). The number of remaining samples was then balanced for attack classes, and the remainder was left for normal traffic. This balance yielded a total training dataset size of 194,845 rows. Although smaller than the final Zahm et al. [1] dataset, it has proportionately less normal traffic (42.9% vs. 66%). Deduplication prevented skewing accuracy figures up by repeatedly processing the same data point and ensuring the test split did not contain samples found in the train set (e.g., if the data point is accurately classified, accuracy becomes inflated). Table 2 shows the distribution of class types where an 80%/20% train/test split was used. Chance performance would be to always declare the majority class of normal and yield 42.9% accuracy.
Full-Precision Neural Network and Hyperparameter Tuning
A fully connected neural network was used for classification. In prior work, encoder units (but not decoder units) of a separately trained autoencoder network combined with a multilayer, fully connected network were used. This resulted in a 10-layer, fully connected neural network (one input layer, four autoencoder layers, and five network layers). The autoencoder was removed due to its highly variable post-training performance across different datasets. This also improved model compatibility with the BrainChip hardware. After spiking neural network (SNN) conversion, Zahm et al.’s model [1] required more than 80 neural processing units. This was over the limit for Akida’s neuron fabric, so only software simulation could be performed. By removing the autoencoder, the model parameter count was reduced, enabling the model to run on the BrainChip’s hardware and allowing timing and power data to be measured.
The “Weights and Biases” grid search [5] was also used to identify optimal hyperparameter values like learning rate, batch size, feature count, and hidden layer sizes. Feature count refers to the number of features chosen from the dataset, ranked by feature importance from a random forest model. Too few features may lead to underfitting, while too many may lead to overfitting. Similarly, as hidden layer widths increase, a risk of overfitting arises, and using too few neurons may underfit the data.
BrainChip Neuromorphic Platform
BrainChip offers the Akida 1000 chip for edge artificial intelligence/machine-learning (AI/ML) applications. These chips perform the inference steps of SNNs. BrainChip provides the CNN2SNN Python toolkit [6] to assist in converting full-precision artificial neural network (ANN) models to Akida-compatible SNN models. Zahm et al. [1] utilized the CNN2SNN toolkit to perform a simple ANN-SNN conversion process, with room for improvement. In this work, the following were explored: (1) the effects of an improved input data scaling process, (2) improved ANN to SNN conversion process, (3) running the converted model on Akida hardware, and (4) measuring model performance, power, and timing on the device.
Input Data Scaling
Data scaling is crucial to optimize SNN performance and needs to be tuned by the dataset and model. Data scaling for SNNs modifies traditionally zero-centered and unit standard deviation scaled data such that its maximum, minimum, and spread optimally cover the target input range. For the Akida system on a chip, this input range is limited to four unsigned bits, or [0, 15], by the hardware.
SNNs have 4- to 8-bit neuron firing rates compared to floating point activations in traditional ANNs. Data must be scaled appropriately to the range of the limited neuron firing rates to maximize the information passed through the network. In Zahm et al. [1], the data was rescaled from 0 to 1. To make it compatible with 4-bit precision, data was then multiplied by 10 and rescaled to a 4-bit unsigned integer.
For this work, outliers outside 95% of the upper range of data and 5% of the lower range were removed and min-max rescaling applied. Versus Zahm et al. [1], this produced a more uniform distribution of the data across the 4-bit range. For example, feature id.resp_p_conn ranged in [0, 8] with the old scaling method but [0, 15] with the new method. The scaled data was then binned to the nearest whole integer in the range. The binned data was divided by 15 to the [0, 1] range, and quantization aware retraining was applied. The final on-chip model inference function was passed scaling factors (x – ab), along with the binned, 4-bit unsigned data.
The effect of data scaling on quantized models and converted Akida SNNs was measured. (Quantization refers to reducing the bit width of an ANN model’s weights and biases from higher to lower precision.) Conversion takes a quantized model and removes training-only features like dropout.
ANN to SNN Conversion
SNNs have lower precision representations in their weights and activation functions compared to ANNs. This allows for simpler hardware due to the removal of floating-point computations—this is one reason why neuromorphic networks use less power with smaller models. However, simply changing the precision of model weights and scaling appropriately does not produce performant models.
Zahm et al. [1] developed the following quantization process: quantize weights to a high, unsigned precision; execute quantization-aware retraining with the original training data; and then convert to a lower precision. Retraining continued until learning plateaued. In this work, more quantization steps were used. The quantization schedule is shown in Table 3. These hyperparameters were determined empirically through grid search. Future exploration could introduce greater granularity into this analysis.
Table 3. Quantization Schedule
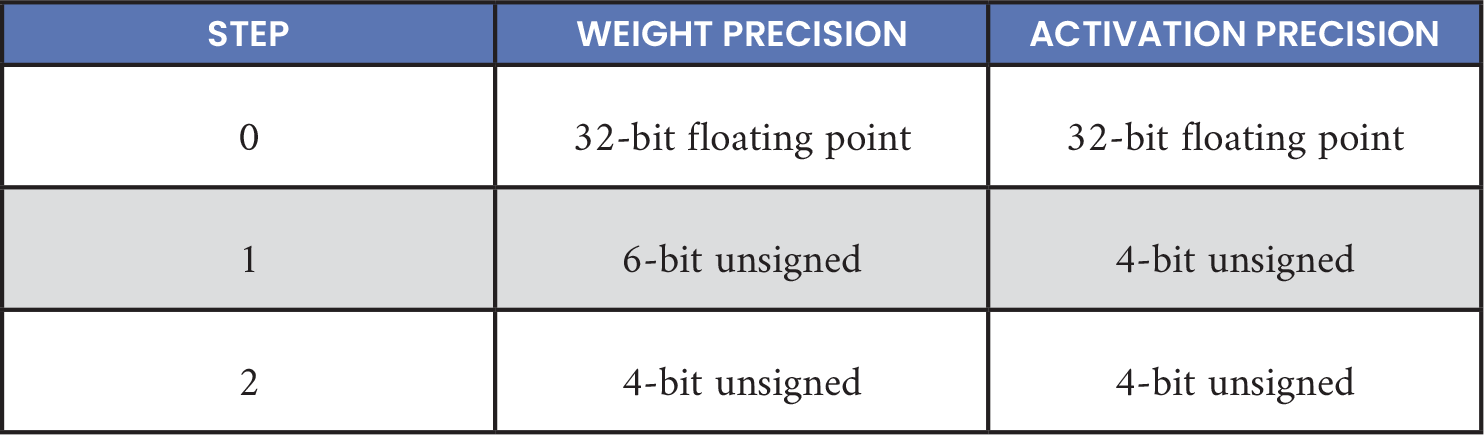
In addition, a monotonically decreasing learning rate schedule was used at each quantization step. Learning rates decreased by a factor of 10 over four steps, thus allowing additional training iterations for fine tuning. The training schedule was set to minimize the number of experiments over the large search space. Future work could use Bayesian methods to determine learning rate schedules for different network architectures or datasets.
On-chip Execution
Zahm et al. [1] leveraged the BrainChip software simulator for SNN execution. This work uses the BrainChip Akida device to analyze SNN model performance.
Intel Neuromorphic Platform
This article focuses on Intel’s latest Loihi 2 chip with their new deep-learning framework, Lava Deep Learning (Lava DL) [7]. Zahm et al. [1] utilized the Loihi 1 architecture combined with the SNN-Toolbox, a software package intended for direct ANN-SNN conversion. The Lava DL software package contains two main modules for training networks compatible with Loihi hardware—Spike Layer Error Reassignment in Time (SLAYER) and Bootstrap. SLAYER is intended for native training of deep event-based networks, and Bootstrap is intended for training rate-coded SNNs.
The Bootstrap module of the Lava-DL accelerates the training of SNNs and closes the performance gap compared to an equivalent ANN. SNNs have extended training times compared to ANNs. This method leverages the similarity between the behavior of the leaky integrate and fire (LIF) neuron and the rectified linear unit activation function to produce a piecewise mapping of the former to the latter. This method of ANN-SNN syncing in training is particularly beneficial because it accelerates the training of a rate-coded SNN, reduces the inference latency of the trained SNN, and closes the gap between ANN and SNN accuracy. The network was trained on either a CPU or GPU, and then inference was performed on the Loihi 2 hardware. Testing on an identically structured network to the Akida hardware tests was performed to compare performance between the two product offerings.
The current-based LIF (CUBA) neuron model, combined with an Adam optimizer, and categorical cross entropy loss were used to train the model. The neuron threshold parameter of the LIF neuron affected performance the most of any of the neuron parameters, so values from 0.25 to 1.5 in steps of 0.25 were tested. If the threshold was too low, performance would suffer due to saturation of neuron activation in the subsequent layers. If the threshold was too high, few neurons would activate at all and the performance of the network would suffer. A value of 0.75 provided the best performance. Altering the default values of the other parameters induced erratic neuron behavior and unstable training.
Hyperparameter Tuning
After identifying a sufficient neuron model for the Lava DL model, further hyperparameter optimization was performed for the batch sizes of 256, 512, and 1,024 transactions and learning rates of 1E-3, 1E-4, and 1E-5. Training was performed for 200 epochs for each model to allow convergence for the lowest learning rates.
Results
Full-Precision Neural Network and Hyperparameter Tuning
While all values had an impact on model performance, hidden layer count and batch size were of greatest value for maximizing model performance. Plotting the average of a performance metric for all sweeps grouped by the parameter of interest also shows these relationships. Increased batch size was correlated with decreased model test accuracy (see Figure 2), and increased parameter count via hidden unit design correlated positively with accuracy (not shown). Larger batch sizes sometimes led to more unstable training and decreased accuracy.
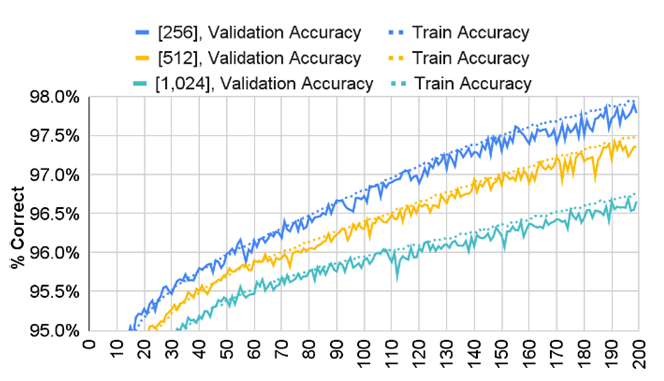
Figure 2. Sweep Mean Train (Dotted Line) and Validation Accuracy (Solid Line) for Different Batch Sizes (Source: Zahm et al.).
By hyperparameter tuning across more than 50 parameter configurations, a model accuracy of 98.42% was achieved on the TON-IoT subset split data with an 80/20 split. This parameter sweep was performed on two NVIDIA A100 nodes and took three hours. Previous hyperparameter sweeps took more time due to larger neural network sizes.
BrainChip Neuromorphic Platform
The following results are presented in this section: an improved data scaling process, an improved ANN to SNN conversion process, and running the converted model on a chip rather than just via software simulator. This gained valuable insights into real hardware inference speeds and power costs.
Data Scaling
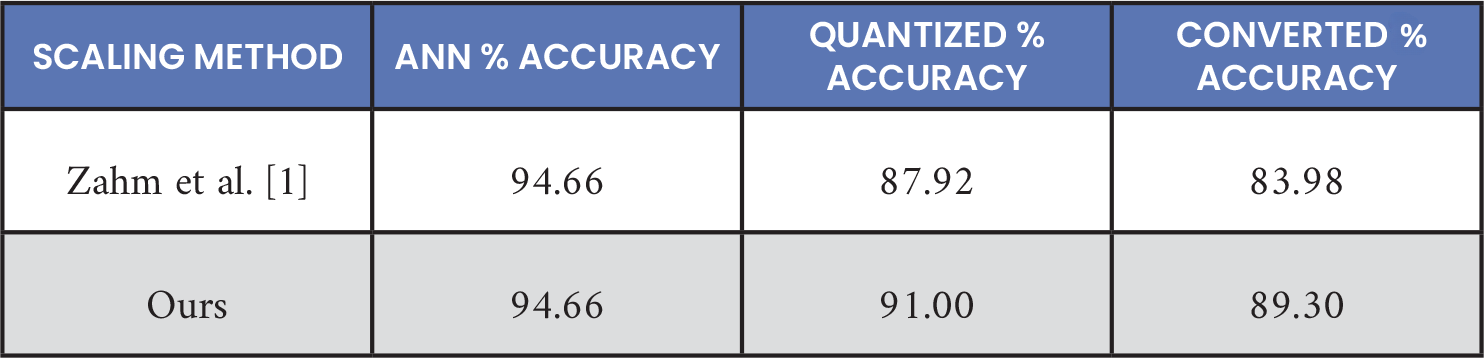
The new data scaling method outperformed the old Zahm et al. [1] method on both quantized and converted SNN models, as shown in Table 4. Quantized model performance improved ~3.1% and converted SNN model performance improved ~5.3%. Log-scaling was also tried but did not perform as well as the new method. The reduced accuracy drop was noted when converting the quantized model to an SNN with the data scaled via the new processes (3.9% vs. 1.7%). Passing scaling factors were also introduced to the SNN model in hardware to further reduce this accuracy loss when converting a quantized model. However, this was not used to produce Table 4, as Zahm et al. [1] used this technique. Data scaling experiments were done for SNN training but not ANN training, hence identical ANN performance. Note that identical initial ANN model and identical quantization retraining schedules were used and not the optimal ANN design and optimal quantization retraining schedules.
Table 4. BrainChip, SNN Data Scaling Technique vs. Performance
ANN to SNN Conversion
In Table 5, quantization yields dramatically smaller models to fit on low SWaP-C neuromorphic hardware. Accuracy increased for the ANN and SNN models, and ANN performance increased 4.7%. At 98.4% accuracy, this was similar to the state of the art presented in Gad et al. [2] and Sarhan et al. [3]. Improvements to the quantization schedule reduced the accuracy drop from 11.2% to 7.2% between full and reduced precision models.
Table 5. BrainChip, Accuracy Benchmarks

On-chip Execution
Results for ANN vs. BrainChip SNN size, power, and speed are summarized in Table 6. Power consumption was ~1 W. GPU power was estimated at 30 W, using 10% of an NVIDIA A100’s maximum power consumption. Speed was slower for neuromorphic chips. GPU models could operate with much higher throughput due to batch processing, which might not be available for streaming cybersecurity data.
Table 6. ANN vs. BrainChip SNN Size, Power, and Speed

Intel Neuromorphic Platform
Batch size was negatively correlated with accuracy, while learning rate was positively correlated with accuracy. Larger batch sizes took longer to converge but were less susceptible to random fluctuations in the dataset. The Bootstrap framework appeared to perform better with larger learning rates, whereas ANNs typically preferred smaller learning rates.
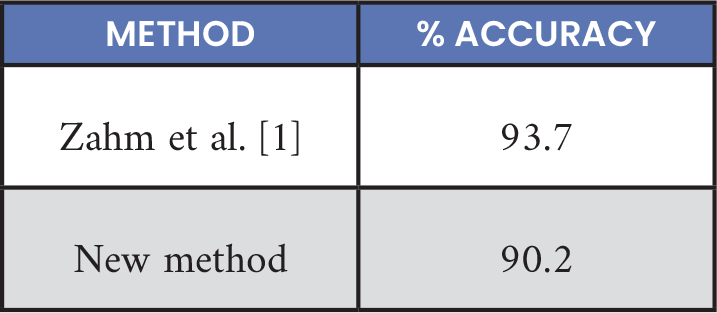
A final accuracy of 90.2% was achieved with the Lava DL Bootstrap framework, with an identical architecture to the Akida network, as shown in Table 7. This was a reduction in accuracy of 3.5% compared to the prior work of Zahm et al. [1]. However, the old SNN-Toolbox performed direct ANN-SNN conversion, while Lava DL required implementation and training of a native SNN.
Table 7. Intel Accuracy
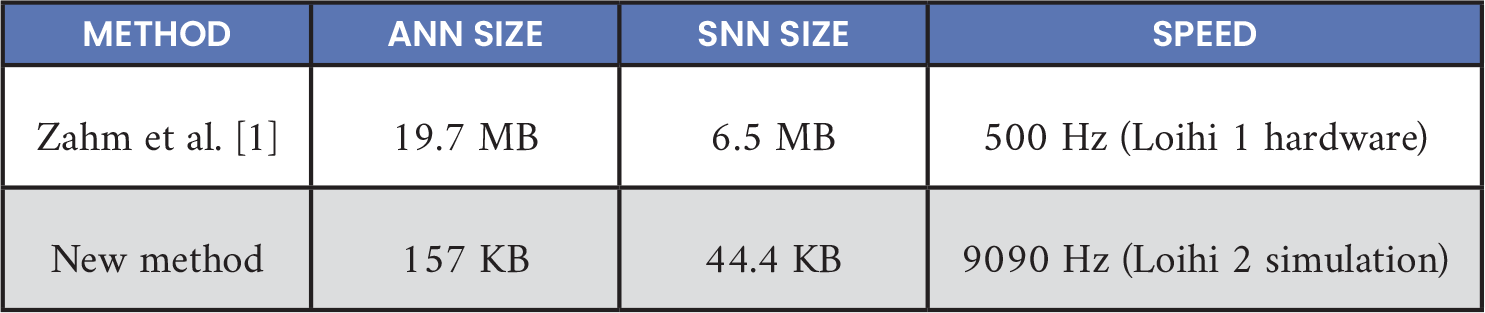
A 72.4% reduction in model size was observed between the full-precision ANN and the Lava DL model detailed in Table 8. With over 24 MB of memory available on Loihi 2 chips, this model is expected to comfortably fit on the hardware.
Table 8. ANN vs. Intel Size and Speed
While the Lava DL network could predict normal traffic 99% of the time, it struggled to accurately predict the precise class of non-normal traffic. The highest classification accuracy in non-normal traffic was 52% for DOS attacks.
Discussion
The following was presented from this work: an improved dataset with less normal traffic and improved ANN performance via better data preprocessing and hyperparameter tuning. For BrainChip, accuracy improved, model size decreased, and the model on the Akida chip was assessed for timing and power. Improvements were attributed to better data scaling and rigorous model quantization and retraining. For Intel, the performance of the new Lava DL framework was benchmarked, with a slight dip in performance compared to the prior SNN-Toolbox. However, accuracy was similar to BrainChip. Although the percentage of correct results (~98%) was like the state of the art presented in Gad et al. [2] and Sarhan et al. [3], low neuromorphic processors could be used with dramatic SWaP-C savings (see Table 1). In related work, a semi-supervised approach to cybersecurity on Intel’s Loihi 2 was investigated [8]. Testing these models on Intel hardware and larger and more diverse datasets is a goal for future work.
Conclusions
Because of their low SWaP-C envelope, neuromorphic technologies are well suited for deployable platforms such as manned aircraft or UAVs. Table 1 illustrates the SWaP-C advantages of neuromorphic processors compared to GPUs. Neuromorphic technologies could be used for cybersecurity of embedded networks or other functions like perception or control. Network traffic across CAN buses, for example, could be passed through neuromorphic processors. These processors would then detect abnormal traffic, which could then be blocked, preventing further harm.
Neuromorphic computing was also pursued for computer vision projects. Park et al. [9] used an ANN to SNN conversion to classify contraband materials across a variety of conditions, such as different temperatures, purities, and backgrounds. Neuromorphic technologies for image processing and automatic target recognition were also explored [10]. For image processing, hierarchical attention-oriented, region-based processing (HARP) [11] was used. HARP removes uninteresting image regions to speed up image transfer and subsequent processing. For automatic target recognition, U-net was used to detect tiny targets in infrared images in cluttered, varied scenes. U-net was run on Intel’s Loihi chip [12].
Research and development in cybersecurity and neuromorphic computing continues, with great potential in both.
Acknowledgments
This material is based upon work supported by the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research program under Award Number DE-SC0021562.
References
- Zahm, W., T. Stern, M. Bal, A. Sengupta, A. Jose, S. Chelian, and S. Vasan. “Cyber-Neuro RT: Real-time Neuromorphic Cybersecurity.” Procedia Computer Science, vol. 213, pp. 536–545, 2022.
- Gad, A., A. Nashat, and T. Barkat. “Intrusion Detection System Using Machine Learning for Vehicular Ad Hoc Networks Based on ToN-IoT Dataset.” IEEE Access, vol. 9, pp. 142206–142217, 2021.
- Sarhan, M., S. Layeghy, N. Moustafa, M. Gallagher, and M. Portmann. “Feature Extraction for Machine Learning-Based Intrusion Detection in IoT Networks.” Digital Communications and Networks, vol. 10, pp. 205–216, 2022.
- Moustafa, N. “New Generations of Internet of Things Datasets for Cybersecurity Applications Based on Machine Learning: TON_IoT Datasets.” In Proceedings of the eResearch Australasia Conference, Brisbane, Australia, pp. 21–25, 2019.
- Weights and Biases. “Weights and Biases.” http://www.wandb.com, accessed on 14 April 2023.
- BrainChip. “CNN2SNN Toolkit.” https://doc.brainchipinc.com/user_guide/cnn2snn.html, accessed on 14 April 2023.
- Intel. “Lava Software Framework.” https://lava-nc.org/, accessed 14 April 2023.
- Bal, M., G. Nishibuchi, S. Chelian, S. Vasan, and A. Sengupta. “Bio-Plausible Hierarchical Semi-Supervised Learning for Intrusion Detection.” In Proceedings of the International Conference on Neuromorphic Systems (ICONS), Santa Fe, NM, 2023.
- Park, K. C., J. Forest, S. Chakraborty, J. T. Daly, S. Chelian, and S. Vasan. “Robust Classification of Contraband Substances Using Longwave Hyperspectral Imaging and Full Precision and Neuromorphic Convolutional Neural Networks.” Procedia Computer Science, vol. 213, pp. 486–495, 2022.
- SBIR.gov. “Bio-inspired Sensors.” https://www.sbir.gov/node/2163189, accessed 14 April 2023.
- Bhowmik, P., M. Pantho, and C. Bobda. “HARP: Hierarchical Attention Oriented Region-Based Processing for High-Performance Computation in Vision Sensor.” Sensors, vol. 21, no. 5, p. 1757, 2021.
- Patel, K., E. Hunsberger, S. Batir, and C. Eliasmith. “A Spiking Neural Network for Image Segmentation.” arXiv preprint arXiv:2106.08921, 2021.
Biographies
Wyler Zahm is a researcher and senior ML engineer. He has worked with advanced algorithms, front- and back-end development, a variety of AI/ML architectures and frameworks such as full precision/GPU and reduced precision/neuromorphic technologies, and applications like automated vulnerability detection and repair for computer source code and cybersecurity. Mr. Zahn has dual bachelor’s degrees in computer engineering and data science from the University of Michigan.
George Nishibuchi is a researcher in materials science and DL. He has a background in computational materials science, with experience running over 50,000 Density Functional Theory simulations at Purdue University’s Network for Computational Nanotechnology, including phonon studies of infrared transparent ceramics, high-throughput studies of semiconductors, and mechanistic studies in solid-state electrolytes. He has also contributed to research in neuromorphic learning algorithms for network intrusion detection systems. Mr. Nishibuchi has an M.S. in materials engineering from Purdue University.
Aswin Jose is a lead system engineer with more than 12 years of extensive experience in system design, software architecture, and leadership. He possesses a broad and deep expertise in various domains such as generative AI/ML verification and validation (V&V), computer vision, big data analytics, the banking sector, logistics, semiconductor technology, healthcare systems, and cutting-edge technological frameworks like full-stack architectures, lambda architecture, and the MEAN stack. Mr. Jose holds an M.E. in computer science from Anna University.
Suhas Chelian is a researcher and ML engineer. He has captured and executed more than $12 million worth of projects with several organizations like Fujitsu Labs of America, Toyota (Partner Robotics Group), HRL Labs (Hughes Research Lab), DARPA, the Intelligence Advanced Research Projects Agency, and NASA. He has 31 publications and 32 patents demonstrating his expertise in ML, computer vision, and neuroscience. Dr. Chelian holds dual bachelor’s degrees in computer science and cognitive science from the University of California, San Diego and a Ph.D. in computational neuroscience from Boston University.
Srini Vasan is the president and CEO of Quantum Ventura Inc. and CTO of QuantumX, the research and development arm of Quantum Ventura Inc. He specializes in AI/ML, AI V&V, ML quality assurance and rigorous testing, ML performance measurement, and system software engineering and system internals. Mr. Vasan studied management at the MIT Sloan School of Management.