


Summary
As data becomes more commoditized across all echelons of the U.S. Department of Defense, developing artificial intelligence/machine-learning (AI/ML) solutions allows for advanced data analysis and processing. However, these solutions require intimate knowledge of the relevant data as well as robust test and evaluation (T&E) procedures to ensure performance and trustworthiness. This article presents a case study and recommendations for developing and evaluating small-scale AI solutions. The model automates an acoustic event location system.
First, the system identifies events across acoustic sensors using an algorithm trained via ML. It then corresponds the events through a heuristic matching process that uses the correspondences and difference of times to multilaterate a physical location. Even a relatively simple dataset requires extensive understanding at all phases of the process. The T&E metrics and pipeline require unique approaches to account for the AI solution, which lacks traceability and explainability. As leaders leverage the growing availability of AI tools to solve problems within their organizations, strong data analysis skills must remain at the core of the process.
Introduction
Like many organizations, the U.S. Army Test and Evaluation Command (ATEC) creates and archives massive amounts of data. Combined with modern advances in analytics, this data has potential to revolutionize business practices. However, the process of identifying useful datasets, developing a model, and then deploying the model safely and responsibly is complex. Though advances of ML and deep-learning models have made great strides in recent years, they are not feasible without a deep understanding of the data upon which they are built.
This article explores using data from an acoustic-based multilateration system to automate what is currently a tedious, labor-intensive process. In a multilateration system, a minimum of three sensors is used to locate an object in space and time by calculating the time differences between the sensors. For the case study, a single test consists of capturing explosive events across a set of 6 to 12 audio channels covering tens of seconds of time, along with metadata about sensor locations, weather station data, and, optionally, the results of preprocessing and manual processing of the data. Engineers manually identify and label the events in each channel. Each audio channel is from a different physical sensor. An example dataset from a single test is shown in Figure 1.
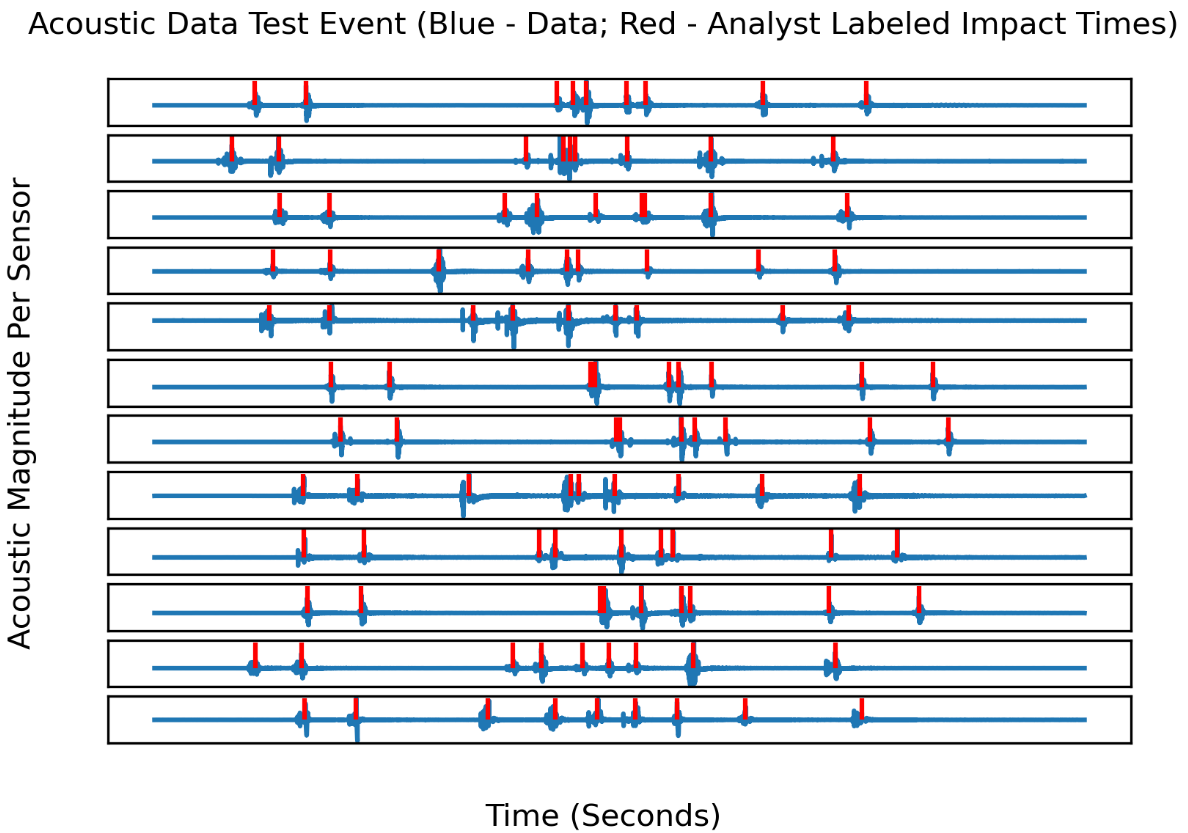
Figure 1. Multilateration Dataset Sample: Blue Lines Depict Acoustic Signals Across 12 Sensors, and Red Dashes Depict Manually Determined Event Labels (Source: D. Niblick and D. Bauer).
Using the multilateration problem as a case study, an architecture is proposed for small teams to develop AI/ML tools to benefit their organizations. Critical steps are illustrated to maximize the chance of success or identify when success is not yet feasible. Teams must become deeply knowledgeable on the data, focus on a useful solution as opposed to fixating on a particular tool, and integrate a requirements-based approached for T&E early in the process. These threads are chronologically separated into a preparation phase, a development phase, and the T&E phase. The phases are broken into subsections based on recommendations and how they apply to this case study.
Preparation
Prior to beginning solution development, teams should assess return on investment (ROI), develop solution requirements with customers, and execute minimal viable experiments (MVEs).
Recommendations
Before committing resources to solve a problem, teams need to deliberately assess the feasibility of a solution and ROI. First steps include assessing the difficulty of the problem, identifying if similar problems have already been solved, analyzing the quality and quantity of the data available, and ensuring relevant expertise exists within the team. There are many ways to quantitatively assess an ROI. However, when making a predictive or automation-based tool, the team must seriously consider the overall process that this tool supports by asking the following questions:
- Will users trust it and want to use it?
- What speed and accuracy are necessary to increase capacity or efficiency?
- Are there safety and ethical considerations that increase the threshold for success?
Many of these nontechnical factors will significantly impact the process and, therefore, the investment required to create a valuable tool.
As soon as possible, the team must interface heavily with the end user to develop a set of preliminary requirements. Requirement development is an iterative process—at the very least, the team and end user must determine some key performance parameters that, if met, will improve the end user’s overall process. These requirements should include prime metrics like accuracy and speed, as well as inputs and outputs between the tool and other software, user interface needs, environments the tool must operate in, cybersecurity, etc., and using quantitative and qualitative metrics.
Before committing resources to full development, the team should execute one or more MVEs. The goal is to isolate the problem into simple terms and see if a solution that achieves a low threshold of success can be quickly built. Although the threshold can change depending on the problem, often even proving a preliminary model does better than “random” is enough to show that the model can learn from the data. The purpose is to determine whether a solution is feasible, identify any aspects not previously considered, refine the requirements, and develop a T&E methodology. Data preparation is critical here, but teams should emphasize speed on a subset of data. During the MVEs, it is helpful to try multiple off-the-shelf models/approaches. The knowledge gained here will benefit development. Additionally, to ensure that the MVEs are successful and justify committing resources to development, a T&E methodology must be established. While this does not need to be perfect, it should integrate T&E into the overall development cycle.
Application to the Multilateration Problem
In the case of the acoustic multilateration tool, there was a significant ROI after interfacing with the end user. The current process included manually identifying the exact timing of bursts in the acoustic channels. The system vendor’s proprietary software automatically scanned the audio data for events but produced numerous false positives. Analysts then went through a lengthy process of moving, deleting, and adding labels to the audio channels. They frequently switched between visual/auditory analysis of individual channels and adjustments to get the best overall solution fit. The tedious label-editing process implements an optimization operation but without the benefits of an optimization algorithm and modern computational capability. Given the frequency of tests that use this system, hundreds of analyst hours were spent on this “cleaning” process every month, so any time savings would have significant impact.
At first glance, the problem appeared relatively easy. The team had access to sufficient quality of labeled data, and multilateration is generally considered a solved problem. The requirement described by the end user was a localization accuracy of 10 m. Speed of application was trivial, as test results already take weeks to finalize. The acoustic multilateration tool operated in a semicontrolled environment. The location was consistent and isolated, and there was flexibility to avoid significant weather events. Identifying the “events” involved separating loud explosions vs. background noise. The difficulty of the multilateration problem existed in not just identifying the explosion but consistently selecting the same moment of time across all explosion detections. Because the explosions are close together in time relative to their separation in space, their shockwaves arrive at the sensors in different orders. This is a major driver of the problem’s complexity.
An MVE was executed to accurately identify and localize the events within the audio. The goal was to find at least 50 percent of the events with a 75 percent recall accuracy. The average time needed to be within 30 ms. During the MVE, a minimal amount of data preparation was conducted, including some manual relabelling on acoustic streams. Accepting risk on the event correlation was decided, as that was expected to be the “easier” phase. In retrospect, this assumption was false. Ultimately, the MVE was a success, and many eccentricities in the data were discovered that affected future algorithm development.
As an example of these eccentricities, the labels were found to be much more inaccurate than initially assumed. Events were generally labeled across all audio channels when each sensor would have been expected to hear the event. However, in many cases, an audio channel did not actually capture the event or the audio was distorted. This caused labels that appeared obviously wrong for their specific audio channel. In addition to lowering the accuracy of ML algorithms that depend on accurate labels, the seemingly bad labels caused trust issues, which hampered development. The team manually labeled or relabeled some of the sample data as part of working around the concerns with the existing labels.
A learning point for the team was to be more careful when accepting risk on portions of the problem. The event correlation task proved much more difficult than anticipated. Additionally, the 30-ms time accuracy target corresponded with a 10-m average error only under otherwise perfect conditions, which was not the case here. Had a second MVE been conducted that focused on proving out potential solutions for event correlation, the issues would have been discovered much earlier in the process and saved much effort during the development phase. Thus, it is important to identify the significant components of the tool during MVE and experiment on each component.
Solution Development
The development process for the multilateration problem iterated through multiple approaches, both for the event-detection and event-matching problems.
Recommendations
The development stage will depend greatly on the problem, the team, and the tools available. In cases like this case study where there was no obvious single approach, the team will need to decide how to allocate time between breadth and depth in exploring options and try to look at the problem from different viewpoints throughout the development process. They may need to incorporate an aspect of a different method or even change the solution approach entirely midway through the project. Similarly, the teams are encouraged to spend more time exploring and verifying data before beginning but be prepared to adapt to surprises at any point in development.
Application to the Multilateration Problem
In parallel to cleaning the data, the team began developing the technical solution through sessions of exploratory analysis and brainstorming. The acoustic multilateration problem was initially addressed as two independent tasks. The first task was to detect signals from events in the audio data. The second was to match up the detections to find the location and time of the events. The multilateration calculation itself was a basic least-squares fit. Alternatives like orthogonal regression [1] were investigated, but efficiency of the least-squares routine used prevailed.
The team began with the assumption that a deep neural network (DNN) would be the best algorithm to detect audio signals. A variety of networks was trained using real data with basic data augmentation. A substantial amount of effort was put into testing DNN architectures and training options in what turned out to be a case of premature optimization. The best DNN models were the ones that had been fine-tuned on the subset of data relabeled by the development team. A parallel effort tested a simpler method of signal detection using a combination of filtering and thresholding. Both methods worked well for clear, unambiguous signals, but both had trouble with noisy audio tracks and overlapping signals.
The final solution to the audio detection discarded the DNN in favor of a simpler, hybrid AI/ML approach. A set of building blocks (e.g., filters, time-domain peak detection, and thresholding) was provided to a genetic algorithm, which produced better-performing detection algorithms than both prior manual efforts and the DNNs. The training data was insufficient in both quality and quantity to train a superior DNN. By providing building blocks—which were determined based on a series of hand-crafted algorithms—the team effectively reverted to an older style of feature engineering. By having far fewer parameters, overfitting the limited training data was avoided.
For the task of matching up detections to determine events, this problem was initially approached as a literal matching problem to solve with integer programming methods. Most of the algorithm work on this task was done using synthetic data, which avoided data quality issues. Early on, it was found that common methods like simulated annealing [2] could consistently solve the matching problem if the set of detections was nearly complete and with very few false positives or false negatives.
Later, the second task was reframed as a continuous optimization problem, which allowed for a much wider variety of algorithms to be used. A variety of algorithms was tested from the SciPy [3], pymoo [4], and pySOT [5] libraries. The best results came from the SciPy package’s DIRECT algorithm [6]. However, none of the optimization algorithms tested could directly solve the entire matching problem under noisy conditions. Instead, the optimizer was used to solve a smaller problem—the set of audio detections which corresponded to a single explosion event. The optimizer became a building block of a larger, heuristic algorithm that determined the sets of audio detections for all events.
Throughout the development process, focus iterated back and forth between the two tasks. It was clear early on that a better solution for the first task made the second task much more accurate. However, what level is possible is still unknown. During development, finding false solution sets with lower residual error than the real solution was possible. The existing manual process is also subject to false solution fits but was not tested. Fear of overfitting also prevented the team from pursuing an algorithm that adjusted labels based on feedback from the event-matching task, as done in the manual process.
T&E
A general framework to conduct T&E for AI/ML solutions should emphasize the role of data, consider conditions and environments, and evaluate risk.
Recommendations
Conducting T&E for AI/ML solutions, even for small-scale solutions, is notoriously difficult and often intractable. AI/ML solutions often exhibit black-box qualities and lack traceability and explainability [7]. It is recommended a portion of the team focus on developing T&E tools and methodologies in parallel to and integrated with the development team. The T&E team should focus not only on quantitative aspects like accuracy but also on how the tool will interface into the overall pipeline, how to ensure end-user trust, etc.
Just as data was central to preparation and development, it is once again central to T&E. The T&E team must be just as knowledgeable on the data as the development team. The team must understand the nuances to the following questions: Does your data represent future operational conditions? Is your data not only balanced in class but in environment and conditions?
When working with problems in the realm of AI, taking a requirements-based approach [8] through the lens of the relevant environment/conditions and communicated through capabilities, limitations, and risk is recommended. Simple metrics such as accuracy and recall are not sufficient for tools that operate under real-world conditions as part of a larger, complex process. Metrics and test design need to deeply consider environment, operational conditions, class balance, etc. The goal of T&E is to go beyond a “pass/fail” assessment and quantify and communicate in terms of environmental risks and end-user conditions. Users should understand in what circumstances their solutions are successful and what circumstances correlate to a higher level of risk. Communicating to the user about model performance risk broken out by conditions helps instill confidence and avoid model misuse.
Once the right metrics are selected, the T&E loop of plan, execute, evaluate, and refine must be as automated and fast as possible. Ideally, following a DevOps model, these tools are integrated to the extent that as soon as the development team updates the solution, they get real-time feedback on the results. Even if tools can be automated, overall T&E is not. The T&E team must understand where risk is involved through the overall pipeline. Does our tool introduce new risk and can that be mitigated somehow? The team must consider how the tool will eventually be used and evaluate against that. This can only be achieved through a “user IN the loop” mentality. To ensure that requirements development follows the customers’ needs, it is recommended to collaborate with them early and often.
Application to the Multilateration Problem
For the multilateration tool, the team collaborated with the users to determine not only the requirements just discussed (such as average location error) but the environment and conditions in which this tool will be used. Metric selection was refined and experiments designed to closely track how the tool performs under different test conditions. When executing the plan, execute, evaluate, refine loop (shown in Figure 2) midway through the development process, it was discovered that the overall average model error was unacceptable. However, the median error was close to the requirement. Due to the refined experiments, the conditions which increased risk for error were elicited. Figures 3–5 show some of the results.
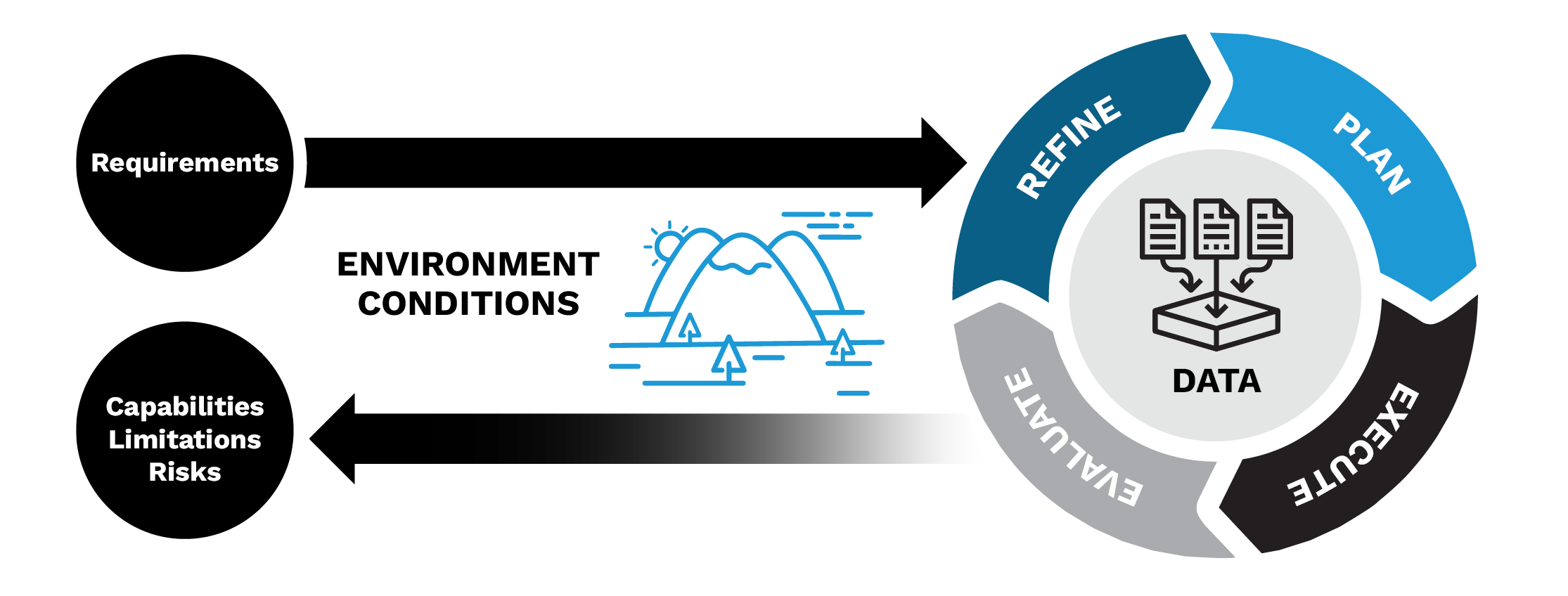
Figure 2. The Plan, Executive, Evaluate, and Refine Loop (Source: D. Niblick and D. Bauer).
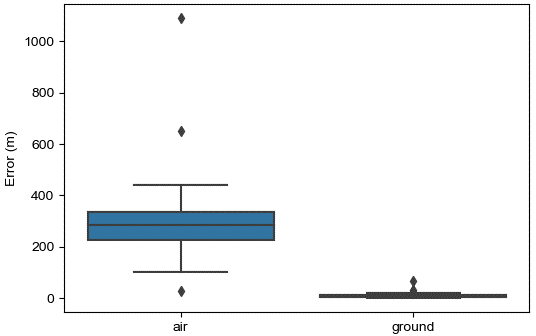
Figure 3. Box Plots Comparing Location Error of Air Burst to Ground Burst Events. A T-Test P-Value of 1.15e-16 Indicates a Strong Correlation of Error to Burst Elevation (Source: D. Niblick and D. Bauer).
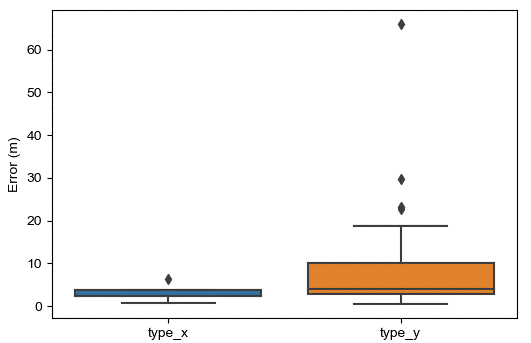
Figure 4. Box Plots Comparing Location Error of Different Munition Types (Ground Burst Only). A T-Test P-Value of 0.28 Indicates Possible Increased Risk of Error With Type Y Munitions (Source: D. Niblick and D. Bauer).
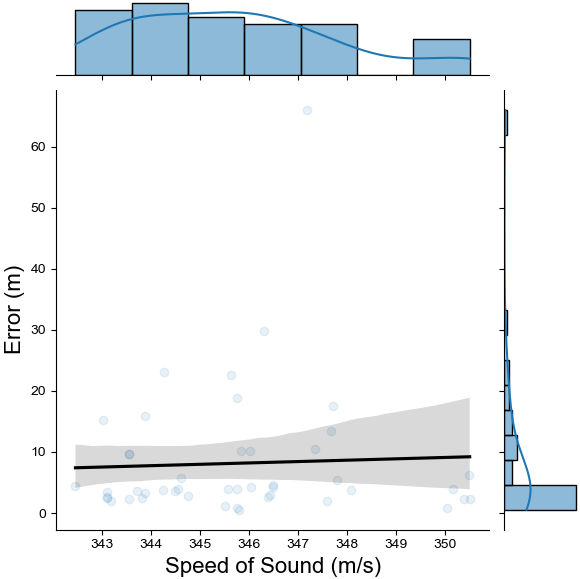
Figure 5. Analysis on Impact of Weather Conditions (Measured as Impact on Speed of Sound) to Model Location Error. The Result Is a Pearson P-Value of 0.78, Which Indicates Insignificant Impact (Source: D. Niblick and D. Bauer).
Based on these outcomes, the model failed requirements at air burst events but succeeded at ground burst events. Atmospheric conditions on days normally selected for tests have minimal impact to accuracy. Though both munition types met the requirement, there was increased risk when using the tool for Type Y munitions. After communicating these results and nuances to the end user, the team discovered a tool successfully multilaterating ground bursts provided significant ROI to their process, and they acknowledged the ongoing work on air-burst multilateration.
Conclusions
There is incredible potential to leverage analytic and AI/ML tools developed by small, in-house teams to solve business problems. However, teams must take a data-centric approach that heavily considers end-user requirements. They must become deeply knowledgeable on the data, focus on a useful solution as opposed to fixating on a particular tool, and integrate a requirements-based approached for T&E early in the process. Although this does not assure the successful deployment of a tool, it minimizes risk in wasted resources by identifying obstacles early and often.
References
- Boggs, P. T., and J. E. Rogers. “Orthogonal Distance Regression” in “Statistical Analysis of Measurement Error Models and Applications: Proceedings of the AMS-IMS-SIAM Joint Summer Research Conference held 10–16 June 1989.” Contemporary Mathematics, vol. 112, 1990.
- Tsallis, C., and D. A. Stariolo. “Generalized Simulated Annealing.” Physica A: Statistical Mechanics and Its Applications, vol. 233, issues 1–2, 1996.
- Virtanen, P., et. al. “SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python.” Nature Methods, vol. 17, no. 3, pp. 261-272, 2020.
- Blank, J., and K. Deb. “Pymoo: Multi-Objective Optimization in Python.” IEEE Access, vol. 8, pp. 89497–89509, 2020.
- Eriksson, D., D. Bindel, and C. Shoemaker. “Surrogate Optimization Toolbox (pySOT).” github.com/dme65/pySOT, 2015.
- Jones, D. R., C. D. Perttunen, and B. E. Stuckman. “Lipschitzian Optimization Without the Lipschitz Constant.” J. Optim. Theory Appl., vol. 79, pp. 157–181, 1993.
- Rudin, C., and J. Radin. “Why Are We Using Black Box Models in AI When We Don’t Need To?” Harvard Data Science Review, https://hdsr.mitpress.mit.edu/pub/f9kuryi8/release/8, accessed on 28 February 2024.
- Whalen, M. W., et al. “Coverage Metrics for Requirements-Based Testing.” Proceedings of the 2006 International Symposium on Software Testing and Analysis, 2006.
Biographies
David Niblick is an artificial intelligence evaluator with ATEC at Aberdeen Proving Ground (APG), MD. He served in the Engineer Branch as a lieutenant and captain at Fort Campbell, KY, with the 101st Airborne Division (Air Assault) and at Schofield Barracks, HI, with the 130th Engineer Brigade. He deployed twice to Afghanistan and the Republic of Korea. He instructed in the Department of Electrical Engineering and Computer Science at the United States Military Academy (USMA) and transferred to Functional Area 49 (Operations Research and Systems Analysis). MAJ Niblick holds a B.S. in electrical engineering from USMA at West Point and an M.S. in electrical and computer engineering from Purdue University, with a thesis in computer vision and deep learning.
David Bauer is an artificial intelligence evaluator with the U.S. Army Evaluation Center at APG, MD, under ATEC. After working as an evaluator of reliability, availability, and maintainability for over a decade, he transitioned to artificial intelligence and machine learning. Dr. Bauer holds a Ph.D. in computer engineering from the Georgia Institute of Technology.