


Summary
Lantern, an innovative adversarial artificial intelligence (AI) workbench with unique features, is presented in this article. Lantern allows users to evaluate adversarial attacks quickly and interactively against artificial intelligence (AI) systems to protect them better. While there has been extensive work in assessing the robustness of AI models against attacks at a large scale, using dataset-level performance evaluations, there is a lack of tools available for designing one-off attacks in real-world scenarios by nonexpert users. Although the existing tools help compare algorithms at a general level, they are not optimized for one-off attacks, which can be better customized for specific scenarios and may therefore be much more effective.
The framework presented here is designed to be compatible with a wide variety of models and attacks and leverages prior work that enables modularity between them in various machine-learning (ML) frameworks. This tool will allow the adversarial AI assurance community to evaluate its efforts beyond automated generic attacks and better understand the threats posed by real-world attacks, which can be individually crafted in a rapid and interactive manner.
Introduction
The last decade has experienced an AI revolution. The introduction of new deep-learning (DL) architectures has led to significant improvements in the performance of ML methods in many different domains, such as computer vision, natural language processing, audio recognition, and others. This, in turn, has caused wide adoption of DL techniques in industry and government applications. However, these same DL algorithms are also known to be vulnerable to adversarial attacks because they can be applied to input data and cause the model to yield incorrect predictions. This vulnerability can cause real-world systems to be unreliable and lower the trust of users in the system.
Therefore, when models are deployed in systems, they need to be tested for vulnerabilities and “shine a light” on the specific adversarial vulnerabilities of the model. A possible solution to this problem is Lantern—an interactive workbench that enables rapid iteration to generate custom-based adversarial attacks. This tool allows users to leverage their domain expertise to hand-tune an attack by quickly iterating and evaluating attack parameters and interactively placing constraints on the attack (e.g., restrict the placement of an adversarial patch to a specific region). Lantern was developed to address a substantial gap observed in the research and software ecosystem surrounding adversarial AI.
Motivation
Although there is extensive work on adversarial AI attacks in the literature examining the effects of different attack methods on the accuracy of neural networks and the ways to reduce these vulnerabilities, many of these do not realistically simulate an adversarial scenario. To publish this work in an academic venue, large-scale experiments must be performed, running the attacks/defenses on many images/models with different parameters and examining the accuracy under different settings to provide statistically significant results. However, this would not be the method used in a realistic adversarial setting.
For example, consider the hypothetical scenario in which adversaries would like to prevent their image from matching another image of themselves that exists in some database while still appearing to the human eye as an unaltered image and a match to their physical self. This would be a clear scenario to use one of the classical adversarial AI techniques like the fast gradient sign method [1], projected gradient descent (PGD) [2], or others to add small perturbations to the image. The slight difference would be changing the loss function from a classification loss to a distance-based loss (as most face recognitions use this type of loss).
However, to produce this attack, adversaries would not have to run thousands of attacks on a large database to find an effective one. Instead, they would try to tailor an attack, including the type of attack and the different parameters, to the specific image they want to manipulate. The attack and parameters would be chosen in such a way that the perturbation is minimally visible for that specific image while the attack itself is successful. To achieve this, adversaries would need to iterate over different settings, observing the visual results (image quality) and attack effectiveness, and choose the specific one that works best.
This is the goal of Lantern—a software workbench which allows careful and iterative crafting of adversarial attacks for a specific data sample and model, thus shining a light (hence, the name Lantern) on vulnerabilities that may exist in a model.
The rest of this article will describe Lantern. First, some background information about adversarial attacks and other adversarial AI tools is provided. Second, the design strategy used in developing Lantern and its features is described. Third, a description of how Lantern is used in practice is presented. Finally, two examples of Lantern use to show its usefulness and versatility are provided.
Background
As described, the goal of Lantern is to provide an interactive and visual interface to implement adversarial evasion attacks of all types. Therefore, two main research directions are presented. First, the attacks themselves are either implementations of or inspired by previous work on evasion attacks in their different forms. As Lantern is an adversarial AI software tool, other packages/libraries highlighting the approach’s novelty are then described.
Adversarial Evasion Attacks
Adversarial evasion attacks are a known vulnerability in DL-based models. As shown as early as 2013 [3], it is possible to slightly perturb input data (in this case, changing pixel values in an image) in such a way that while the perturbation is nearly imperceptible to humans, it completely changes the output of a DL model. Since this discovery, there have been thousands of papers discussing different ways of calculating this perturbation and attempting to improve on each other in three main dimensions—the effectiveness of the perturbation in switching the model decision, how perceptible the perturbation is, and how quickly the perturbation can be calculated [1, 2, 4].
As this is not a survey of adversarial AI, all the different methods and terminology that exist in this field (Zhang [5] provides a good overview of the subject) are not covered. However, one of the main strengths of Lantern is that it allows users to run different attack methods with different parameters. Figure 1 defines some basic terms for such methods.

Figure 1. Overview of Common Adversarial AI Terminology (Source: S. Young).
To evaluate the effectiveness of their attack methods, previous works have usually focused on the attack success rate (ASR) metric. The evaluated attack model is run on a large dataset, generating perturbations for each image. Then, the percentage of misclassifications of the perturbed images is defined as the ASR. However, as described in the Motivation section, this may not always be the ideal way to evaluate the effectiveness of an attack since an adversary would usually not attack in bulk. On the other hand, Lantern allows customization of the attack method and parameters in addition to immediate visual feedback, which provides a more realistic scenario for attack generation.
Adversarial AI Software Packages
Given the impact of evasion attacks on AI trustworthiness and the need to evaluate models under adversarial conditions, numerous libraries have been developed. These usually provide a set of attacks and an interface for using them on models built using different DL libraries.
For example, the Adversarial Library [6] is a library that provides several attacks and other utilities useful for generating and evaluating evasion attacks. Although it contains many types of attacks from the literature, it is somewhat limited since it focuses only on white box attacks and only for segmentation and classification cases. In addition, as this library is written using the PyTorch framework, it focuses on attacking models generated by that framework. This limits its applicability to the more general case in which models will be implemented using different DL libraries.
Lantern uses one of the most extensive and flexible libraries for adversarial AI—the Adversarial Robustness Toolbox (ART) [7]. ART is an open-source library hosted by the Linux Foundation AI & Data Foundation and partially funded by the Defense Advanced Research Projects Agency. It contains over 30 built-in evasion attacks (in addition to other types of attacks) and supports models from all major ML frameworks like TensorFlow, Keras, PyTorch, MXNet, etc. This comprehensiveness in both attacks and frameworks provides Lantern an excellent base on which to build and provides users interface, flexibility, and visual feedback that can harness the power of ART to provide more customizable attack generation.
Software Design and Features
Lantern is designed to enable the rapid integration of new attacks and models. Thus, the software is designed to (1) be interactive so experiments can be tailored to specific images; (2) be extremely modular, utilizing multiple inheritance to allow users to quickly bring in multiple interface tools for a given task, model, or attack; and (3) exploit introspection to automatically populate the user interface. The goal is to allow ML scientists to rapidly integrate attacks, models, and defenses into an interactive user interface that they can leverage themselves or provide it to nondevelopers for demonstration or experimentation. The two libraries mostly utilized to implement Lantern are Streamlit and ART.
Streamlit [8] is an open-source Python framework designed to allow data scientists to quickly develop dynamic Web applications in a way that aligns with how they write code. It was chosen due to its ease of use and large user base that has contributed to many third-party user interface widgets. It allows developers to quickly add Web app features to data science workflows rather than needing to create a separate Web app that lies outside their workflow. ART is used as the library to allow attacks, models, and defenses to be integrated into a single experiment for all the reasons outlined in the previous section.
Design Principle 1: Modularity
To be useful to an ML scientist experimenting with AI security, it is necessary to ensure that the framework is modular. That is, it needs to provide the ability to quickly test against different models, defenses, and attacks and add user interface features. To accomplish this, the modularity that already exists in IBM’s ART for swapping out models, defenses, and attacks is leveraged. By utilizing multiple inheritance, Lantern also provides the ability to add default sets of user interface features to a new attack or model. For example, in Figure 2, a new class named LanternMaskedProjectedGradientDescent was created that inherits from Lantern’s BasicMaskedAttack and ART’s ProjectedGradientDescent. By doing this, an interactive mask can be added to any ART attack supporting the mask keyword argument with class inheritance only and no actual class implementation. Since the user interface is implemented in Streamlit, a large library of Streamlit widgets designed for data scientists can be used.
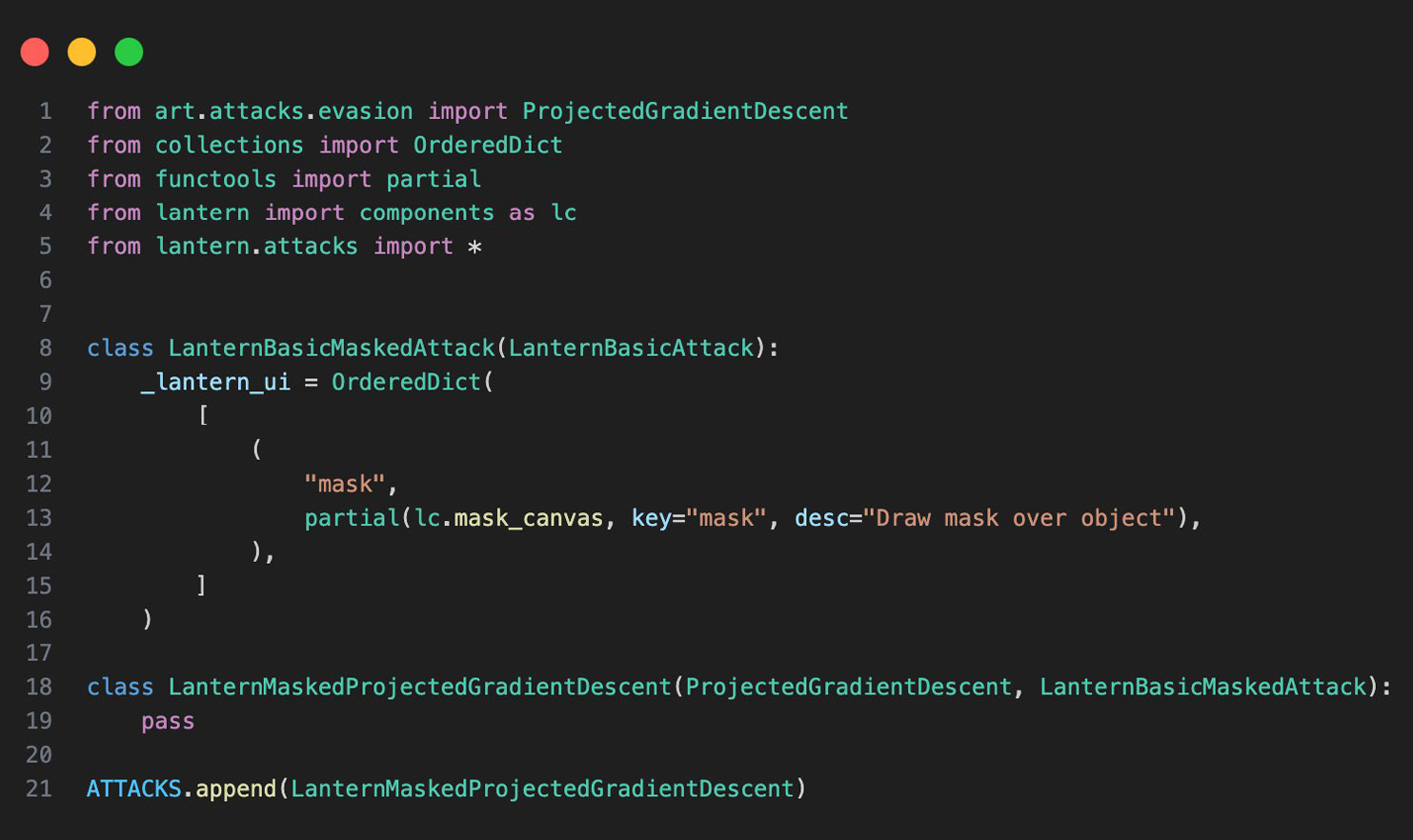
Figure 2. Code Snippet Implementing a Masked Projected Gradient Descent Attack (Source: S. Young).
Design Principle 2: Exploiting Introspection
To decrease the amount of time required to integrate a new model or attack into Lantern, introspection is exploited. The information is leveraged in the code implementing the attacks and models themselves to prepopulate user interface features to eliminate boilerplate code. As each attack may require a different set of parameters, developers should not have to spend time redefining the user interface. To achieve this flexibility, introspection was necessary. By utilizing Python’s inspect package, the default parameters are collected for attacks and models to infer their type and automatically populate the user interface with input elements for parameter adjustments.
Lantern Functionality
To highlight how Lantern’s design principles provide an easy and flexible workbench, two of the available features crucial for its usefulness are presented. First, adding new evasion attacks and implementing a UI feature that allows users to draw a mask over the subject image is described. As new attacks are developed almost daily, it is important to provide an easy and fast way to plug in novel attacks with minimum coding effort. How new models can be integrated is described next. As this tool is geared toward testing existing models, it is important to provide the ability to add models of different architectures which can use different DL libraries.
Adding Evasion Attacks
Adding an attack to Lantern is as simple as adding a few lines of code. First, it is assumed that the attack is a child class of ART’s EvasionAttack class, the actual attack is fully implemented, and default parameters are provided for the attack. Once this is complete, the developer simply needs to define any UI features needed beyond the defaults by creating a dictionary containing any additional parameters to pass to the attack. Some common UI features are available under the lantern.utils submodule, but the developer can add any desired Streamlit widget. A simple example is given in Figure 2, where the code snippet implements a masked projected gradient descent attack that allows users to draw a mask over the portion of the image where the attack should be placed.
Adding Models
Adding a new model to Lantern is very similar to adding a new attack. It is assumed that the model has already been implemented as a KerasClassifier, PytorchClassifier, TensorflowClassifier, or MXClassifier. Depending on the base class, different attacks and features may be available. The developer can also add any UI features that might be required by the model similar to the way they are added for attacks. In Figure 3, a simple example of adding a Keras model is given. The exact details of adding a model will vary for each model’s backend (e.g., Keras, Tensorflow, PyTorch, etc.).

Figure 3. Code Snippet Implementing a ResNet50 Using Keras (Source: S. Young).
Example Scenarios
To show the flexibility of Lantern, two examples are provided where it is used to generate attacks through various methods. These highlight the usefulness of some of the features included in Lantern and how it can be used to generate and evaluate custom-made adversarial attacks.
Attacks on Image Classification Models
First, a simple attack against an object classification model is demonstrated. In this case, the adversary is attacking a model which tries to recognize the type of object existing in an image. More specifically, the adversary is trying to take an image of a minivan and have the model incorrectly recognize it as a sports car (see Figure 4). The model is defined as shown in Figure 3, and the attack is defined as shown in Figure 2.
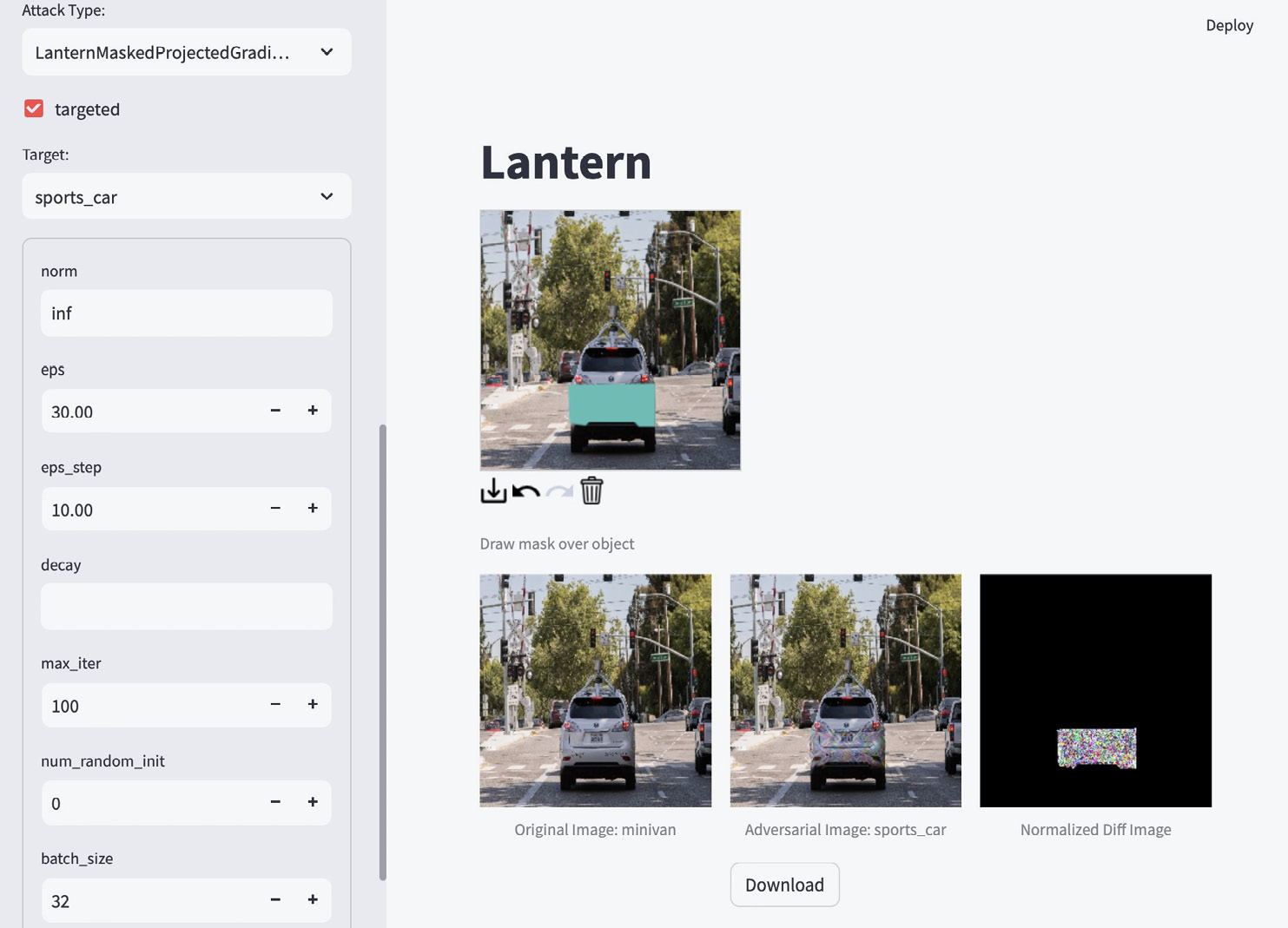
Figure 4. An Example of Using Lantern to Generate Attacks on an Image Classification Task (Source: S. Young).
To generate the attack, the user first selects the model and uploads the image to use as the base for the evasion attack (in this case, the minivan image). Then, the user selects the attack to use, adjusts parameters, masks the region to contain the attack, and then runs the attack. For example, in this example (Figure 4), the attacker restricts the perturbation area to the bumper area of the minivan. In addition, the attacker selects a targeted attack—attempting to convert the minivan into a sports car. After the attack image is generated, the original image, the adversarial image, and the difference image are displayed. As can be seen in the figure, the attack is successful since the model is classifying the altered image as a minivan (middle image on the bottom), while the perturbation is contained in the desired area (rightmost image on the bottom).
Attacks on Face Recognition
In this example, attacking a face recognition model using an out-of-the-box attack is demonstrated. The ArcFace model [9] is implemented as an end-to-end PyTorch model. The PGD [2] attack available in ART is then applied. Figure 5 shows the result achieved by using the default attack with different values of ϵ. As can be seen, the attacker would be able to quickly identify that attacks with an ϵ-value of greater than 0.1 would clearly be noisy and suspicious.

Figure 5. An Example of Using Attack Imagery Generated Using Lantern to Understand the Effect of a Single PGD Setting, ϵ (Source: S. Young).
In fact, since the attack is visible at this ϵ-value, the adversary may try and change other parameters. Figure 6 demonstrates the result achieved after tuning the parameters in the interface. For example, the image on the right uses the L1 distance vs. the L2 distance used in the original attack. The rapid iteration enabled by Lantern enables users to quickly transform the performance of standard attacks from ineffective and obvious to highly effective and subtle.

Figure 6. A Comparison of Results Before and After Using Lantern Tune PGD Attack Settings to Increase Effectiveness and Subtlety (Source: S. Young).
Conclusions
Lantern represents an advancement in robust AI research by enabling AI security researchers to develop adversarial AI-based experiments quickly and efficiently, enabling them to select attack parameters and effects. This is modular and enables rapid experimentation and development of attacks and defenses. The intended user base includes ML scientists and AI security researchers, but the tool also has value for demonstrating adversarial concepts to nonexpert users so they can better understand how adversarial AI would likely be used with a human attacker to create highly effective attack data. Prospects to gain a greater understanding of the robustness (or lack thereof) of these systems include integrating tools like Armory [10] so that more quantitative results can be shown to users like effective attack and defense conditions.
Acknowledgments
Research in this article was sponsored by the Laboratory Directed Research and Development Program of Oak Ridge National Laboratory and managed by UT-Battelle, LLC, for the U.S. Department of Energy (DOE).
Note
This manuscript has been authored by UT-Battelle, LLC, under contract DE-AC05-00OR22725 with the DOE. By accepting the article for publication, the publisher acknowledges that the U.S. government retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this manuscript or allow others to do so for U.S. government purposes. The DOE will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan (https://www.energy.gov/doe-public-access-plan).
References
- Goodfellow, I. J., J. Shlens, and C. Szegedy. “Explaining and Harnessing Adversarial Examples.” arXiv preprint 1412.6572, 2014.
- Madry, A., A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. “Towards Deep Learning Models Resistant to Adversarial Attacks.” International Conference on Learning Representations, 2018.
- Szegedy, C., W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus. “Intriguing Properties of Neural Networks.” arXiv preprint 1312.6199, 2013.
- Kurakin, A., I. Goodfellow, and S. Bengio. “Adversarial Machine Learning at Scale.” ICLR Conference, arXiv preprint 1611.01236, 2017.
- Zhang, J., and C. Li. “Adversarial Examples: Opportunities and Challenges.” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 7, pp. 2578–2593, 2020.
- Rony, J., and B. Ayed. “Adversarial Library [Computer Software].” Zenodo, https://doi.org/10.5281/zenodo.5815063, February 2024.
- Nicolae, M.-I., M. Sinn, M. N. Tran, B. Buesser, A. Rawat, M. Wistuba, V. Zantedeschi, N. Baracaldo, B. Chen, H. Ludwig, I. Molloy, and B. Edwards. “Adversarial Robustness Toolbox v1.2.0.” CoRR, vol. 1807.01069, 2018.
- Streamlit. “Welcome to Streamlit.” https://github.com/streamlit/streamlit, 2024.
- Deng, J., J. Guo, N. Xue, and S. Zafeiriou. “Arcface: Additive Angular Margin Loss for Deep Face Recognition.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4690–4699, 2019.
- Slater, D., and L. Cadalzo. “Two Six GARD Armory (0.16.4).” Zenodo, https://doi.org/10.5281/zenodo.7561756, 2023.
Biographies
Steven Young is a research scientist at Oak Ridge National Laboratory (ORNL) in the Learning Systems Group, where his research focuses on the intersection of DL and high-performance computing. Dr. Young holds a B.S. in electrical engineering and a Ph.D. in computer engineering from the University of Tennessee.
Joel Brogan leads the Multimodal Sensor Analytics Group at ORNL, focusing on emerging biometric capabilities and adversarial red teaming of foundation models. He has developed techniques for image and video forensics, deepfake detection, and biometric reconstruction. He is a founding member of the Center for AI Security Research, where he contributed to government advisory panels, White House reports, and international federal collaborations. Dr. Brogan holds a B.S. in electrical engineering and an M.S. and Ph.D. in computer science and engineering from the University of Notre Dame.
Colin Smith is a ML research scientist at ORNL in the Data Science and Visualization Group, where he applies a broad range of ML techniques to various national security domains, including intelligence analysis, nuclear nonproliferation, and software security. Mr. Smith holds a B.S. in finance from the New York University Stern School of Business Colin and an M.S. in data science from the University of Edinburgh. He is pursuing a Ph.D. in data science and engineering from the University of Tennessee, Knoxville.
Edmon Begoli is a founding director of ORNL’s Center for AI Security Research (CAISER) and distinguished member of the ORNL research staff, where he specializes in the research, design, and development of resilient, secure, and scalable ML and analytic architectures. He has been leading national programs focused on AI security, fraud prevention, veteran suicide prevention, precision, and personalized medicine. Dr. Begoli holds a B.S. and M.S. from the University of Colorado-Boulder and a Ph.D. in computer science from the University of Tennessee.
Amir Sadovnik is a senior research scientist and research lead for CAISER at ORNL where he leads multiple research projects related to AI risk, adversarial AI, and large language model vulnerabilities. Dr. Sadovnik holds a bachelor’s degree in electrical and computer engineering from The Cooper Union and a Ph.D. in electrical and computer engineering from Cornell University.